HumanEval-V is a novel benchmark designed to evaluate the ability of Large Multimodal Models (LMMs) to understand and reason over complex diagrams in programming contexts. Unlike traditional multimodal or coding benchmarks, HumanEval-V challenges models to generate Python code based on visual inputs that are indispensable for solving the task. Our dataset consists of 253 human-annotated coding tasks, each requiring LMMs to perceive, interpret, and reason over diagrams to produce functionally correct code solutions.
Despite recent advancements in multimodal reasoning, existing benchmarks focus primarily on scientific, mathematical, chart-based analysis, or abstract visual reasoning (in IQ tests), assessing models' domain knowledge or deduction abilities. These benchmarks don't fully challenge models to understand complex diagrams in the way that humans do.
HumanEval-V addresses this gap by introducing coding tasks where the diagram alone encodes most of the problem context. Models must perform advanced visual reasoning without relying on lengthy textual descriptions, pushing the boundaries of vision reasoning capabilities.
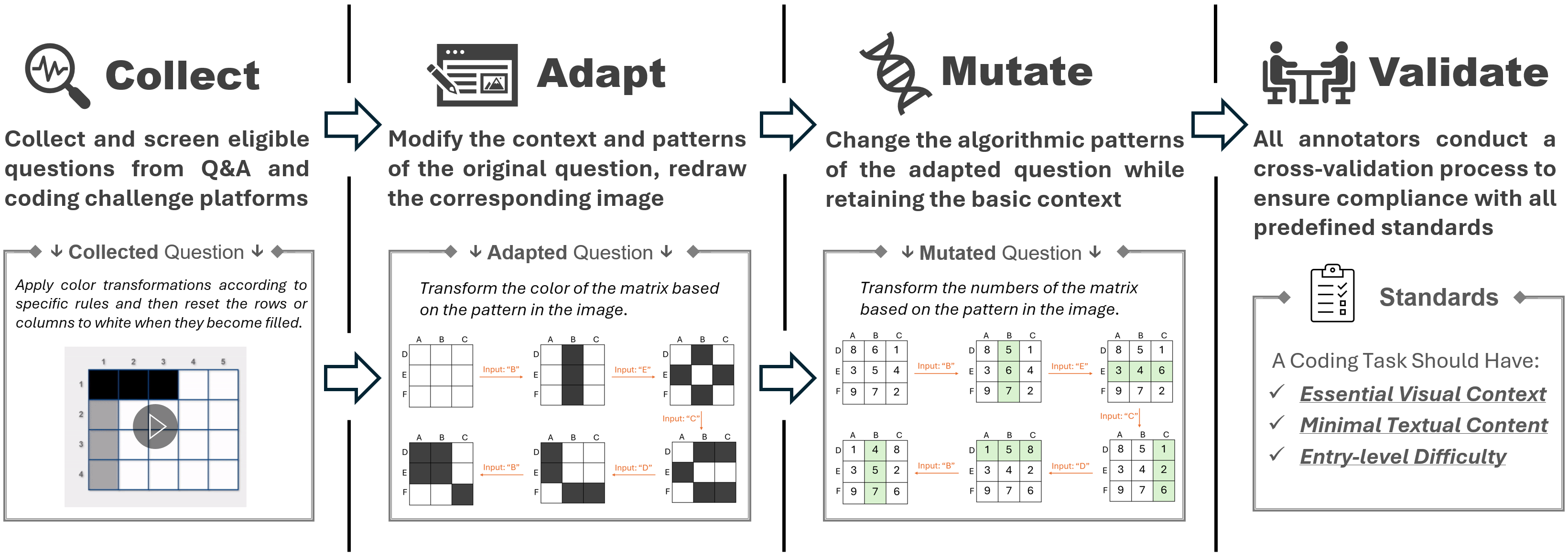
We construct HumanEval-V following a collect-distill-recreate-diversify pipeline. After constructing the benchmark,
we perform rigorous validation to ensure that each coding task aligns with high-quality standards.

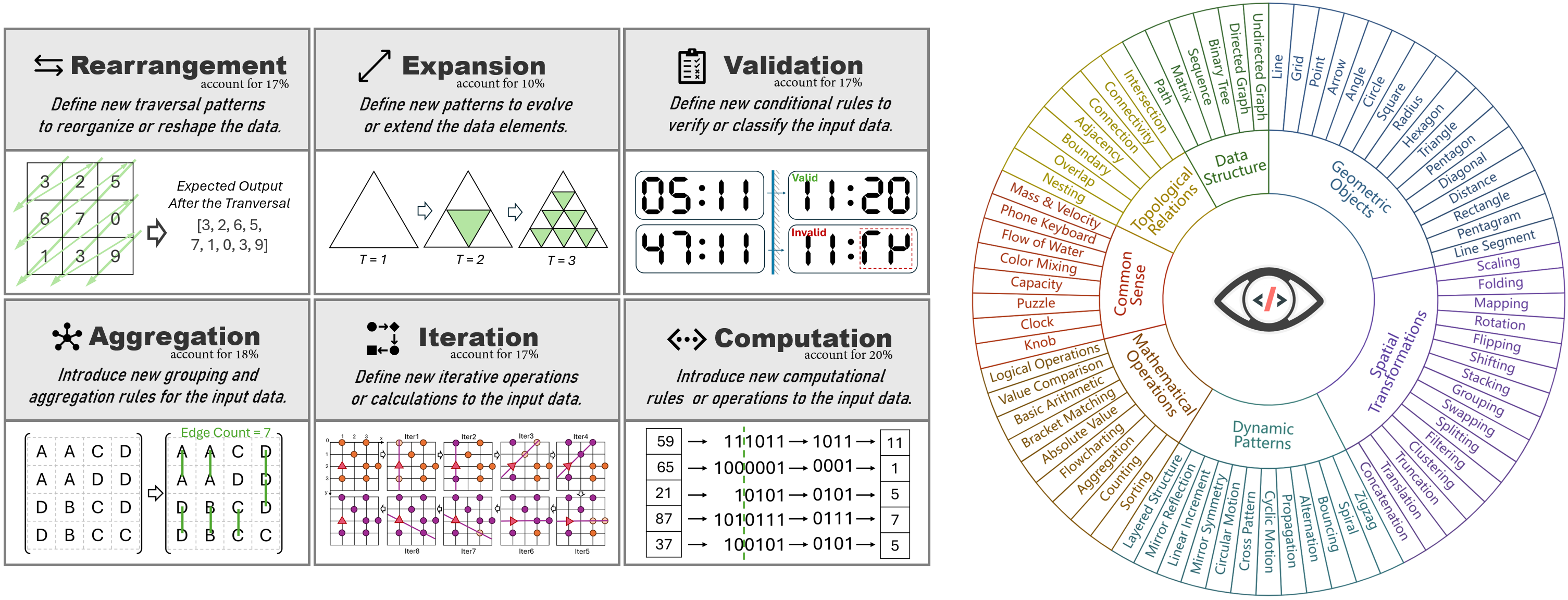
HumanEval-V includes visual elements like trees, graphs, matrices, maps, grids, flowcharts, and more. The visual contexts are designed to be indispensable and self-explanatory, embedding rich contextual information and algorithmic patterns.
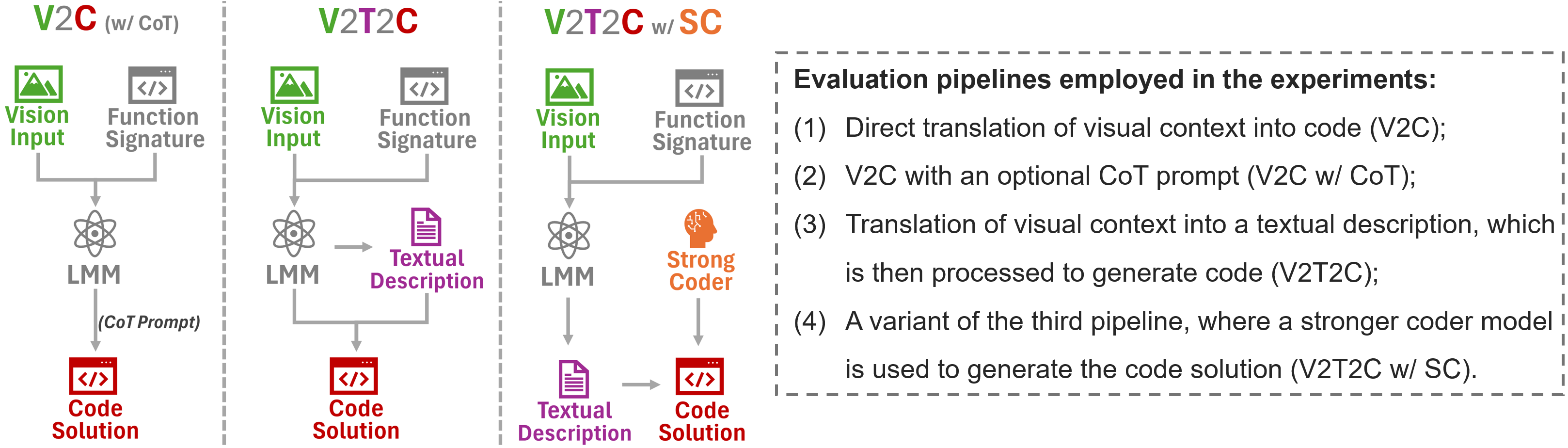
We use a structured evaluation pipeline to assess visual reasoning and coding efficiency separately,
ensuring that models' abilities are evaluated in a decoupled manner.
The best performance is shown in bold, while the second-best is indicated by underlining.
You can sort pass@1 or pass@3 by clicking on the column headers.
| Models | Source | V2C | V2C w/ CoT | V2T2C | V2T2C w/ GPT-4o | ||||
|---|---|---|---|---|---|---|---|---|---|
| pass@1 | pass@3 | pass@1 | pass@3 | pass@1 | pass@3 | pass@1 | pass@3 | ||
@article{zhang2024humanevalv,
title={HumanEval-V: Benchmarking High-Level Visual Reasoning with Complex Diagrams in Coding Tasks},
author={Zhang, Fengji and Wu, Linquan and Bai, Huiyu and Lin, Guancheng and Li, Xiao and Yu, Xiao and Wang, Yue and Chen, Bei and Keung, Jacky},
journal={arXiv preprint arXiv:2410.12381},
year={2024},
}
